Abstract
Human interactions in everyday life are inherently social, involving engagements with diverse individuals across various contexts. Modeling these social interactions is fundamental to a wide range of real-world applications.
In this paper, we introduce SocialGen, the first unified motion-language model capable of modeling interaction behaviors among varying numbers of individuals, to address this crucial yet challenging problem. Unlike prior methods that are limited to two-person interactions, we propose a novel social motion representation that supports tokenizing the motions of an arbitrary number of individuals and aligning them with the language space. This alignment enables the model to leverage rich, pretrained linguistic knowledge to better understand and reason about human social behaviors. To tackle the challenges of data scarcity, we curate a comprehensive multi-human interaction dataset, SocialX, enriched with textual annotations.
Leveraging this dataset, we establish the first comprehensive benchmark for multi-human interaction tasks. Our method achieves state-of-the-art performance across motion-language tasks, setting a new standard for multi-human interaction modeling.
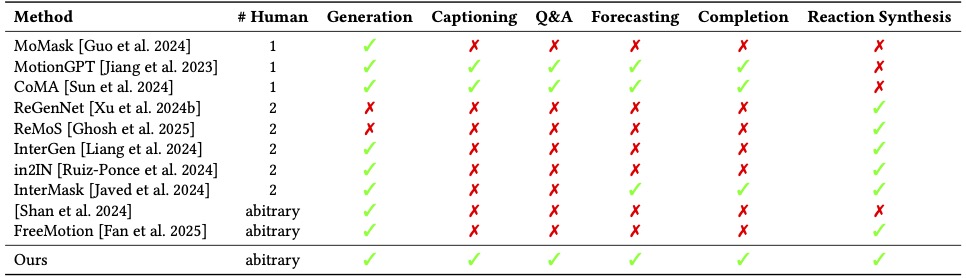
Summary of various methods based on tasks
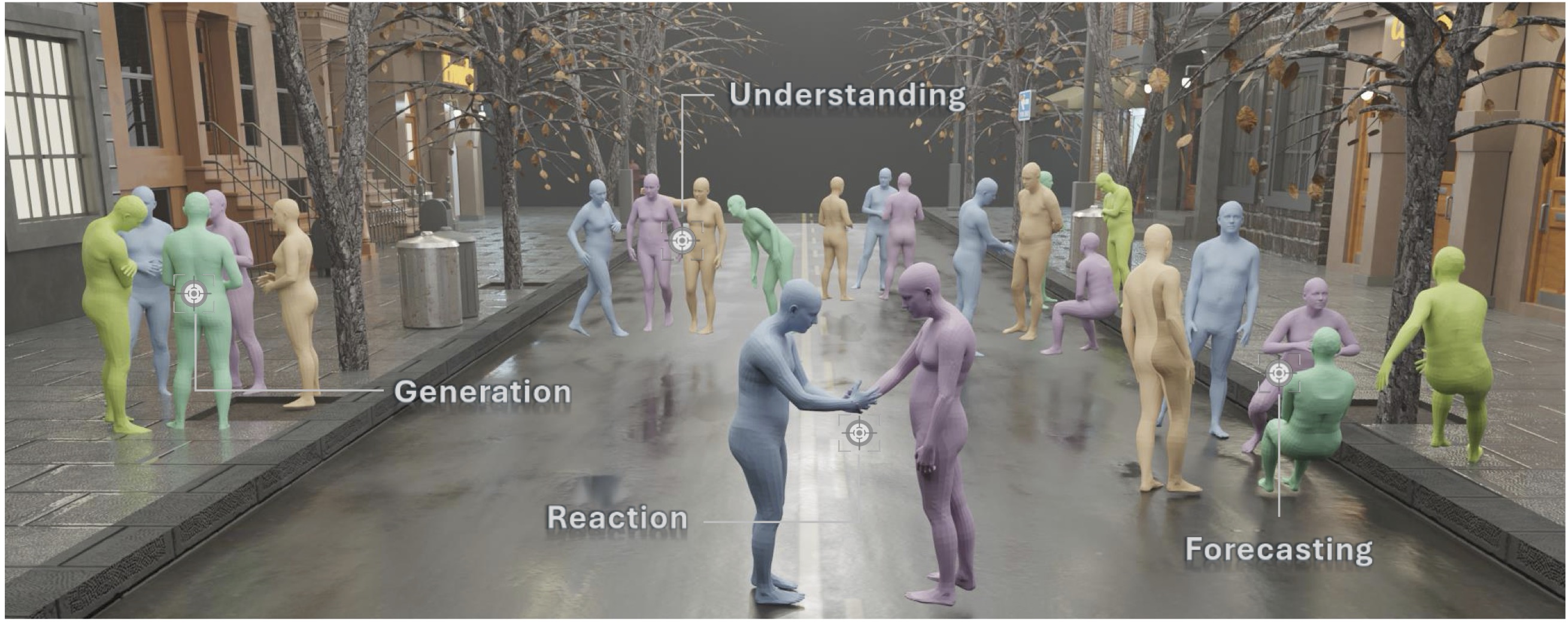
Our model not only handles arbitrary number of people as input and output but is also capable of both generation and understanding social interactions, supporting an array of tasks including captioning, forecasting, reaction generation and etc.
SocialGen Framework
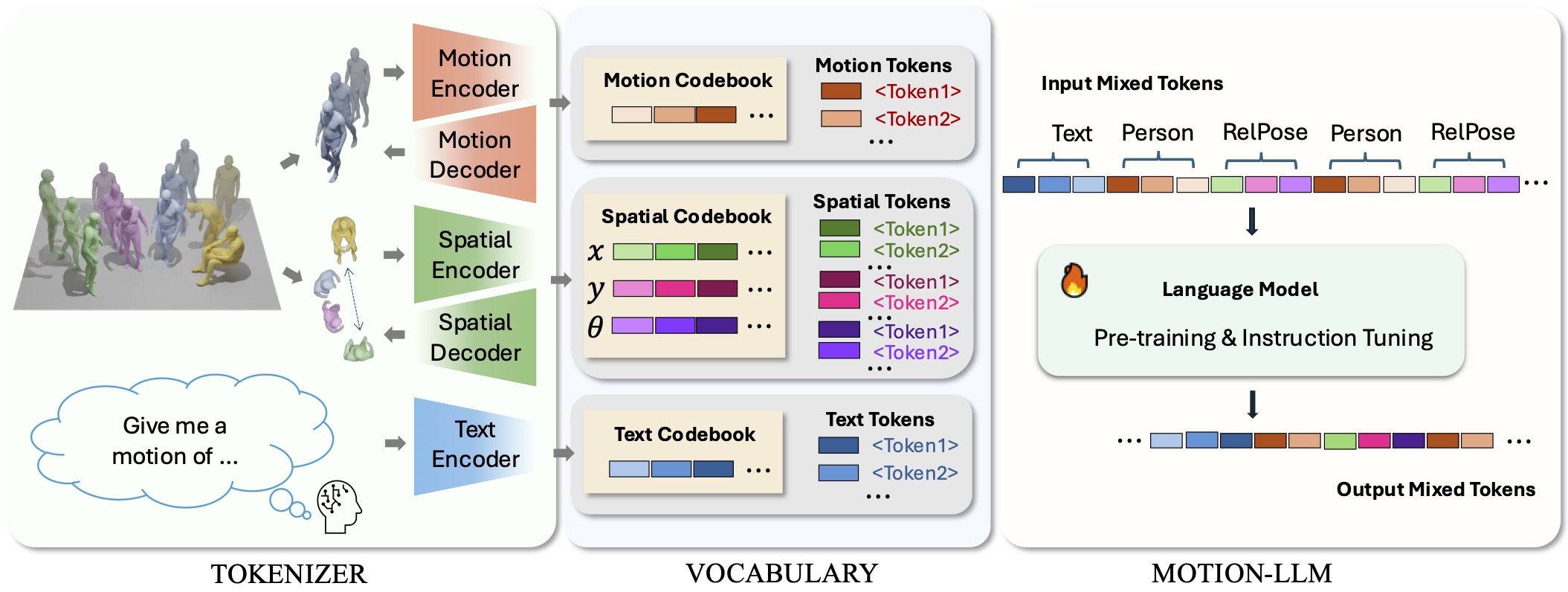
SocialGen unifies motion generation, understanding, and other motion-language tasks for multi-human social interactions. The tokenizer encodes motion, spatial, and text features into tokens via respective codebooks, forming a unified vocabulary of motion, spatial, and text Tokens. These tokens, combined into mixed input tokens representing text, individuals, and relative spatial configurations, are processed by the Motion-LLM, which leverages pre-training and instruction tuning to generate mixed tokens, enabling versatile modeling of complex social interactions.
Visualization
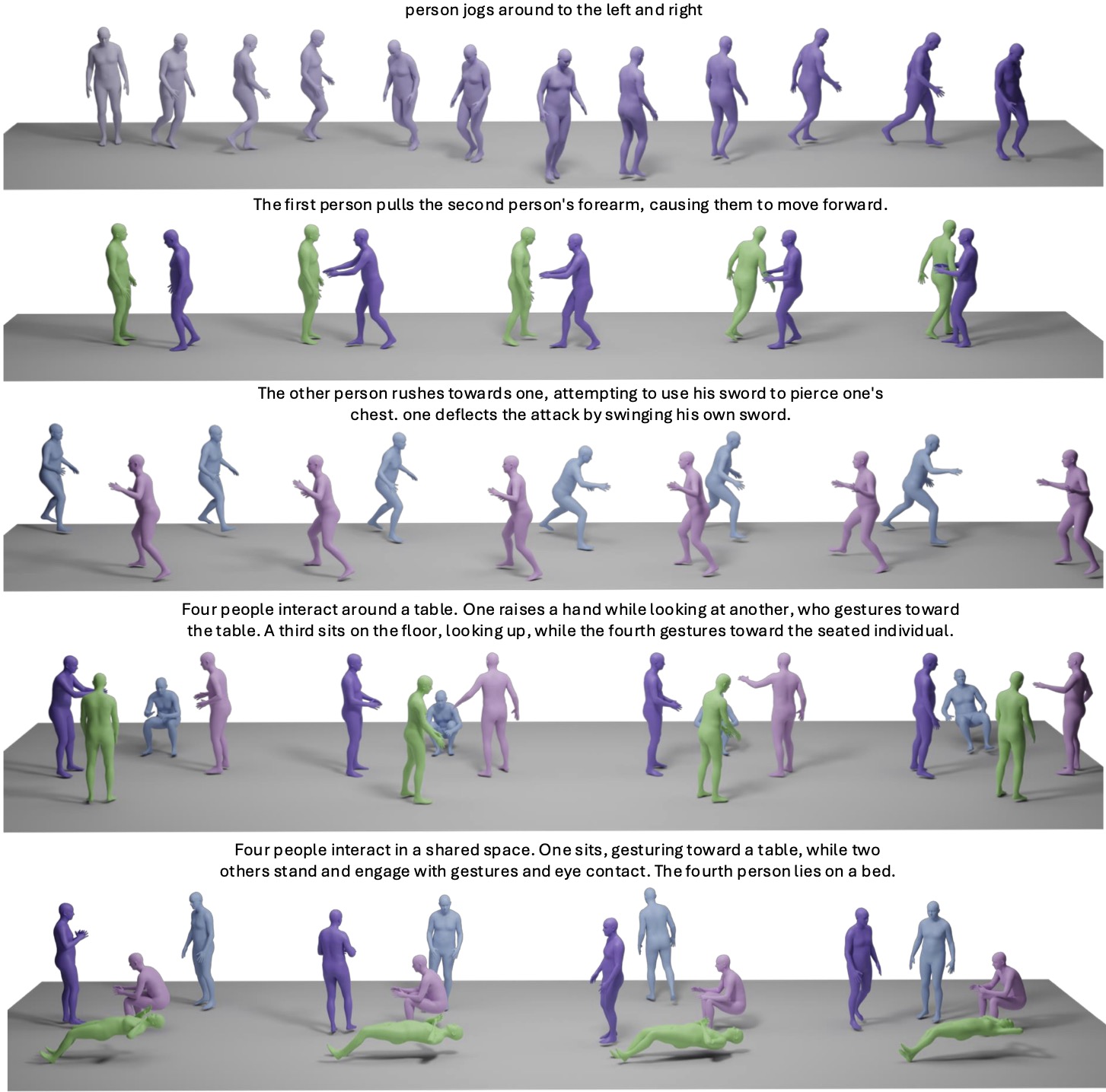
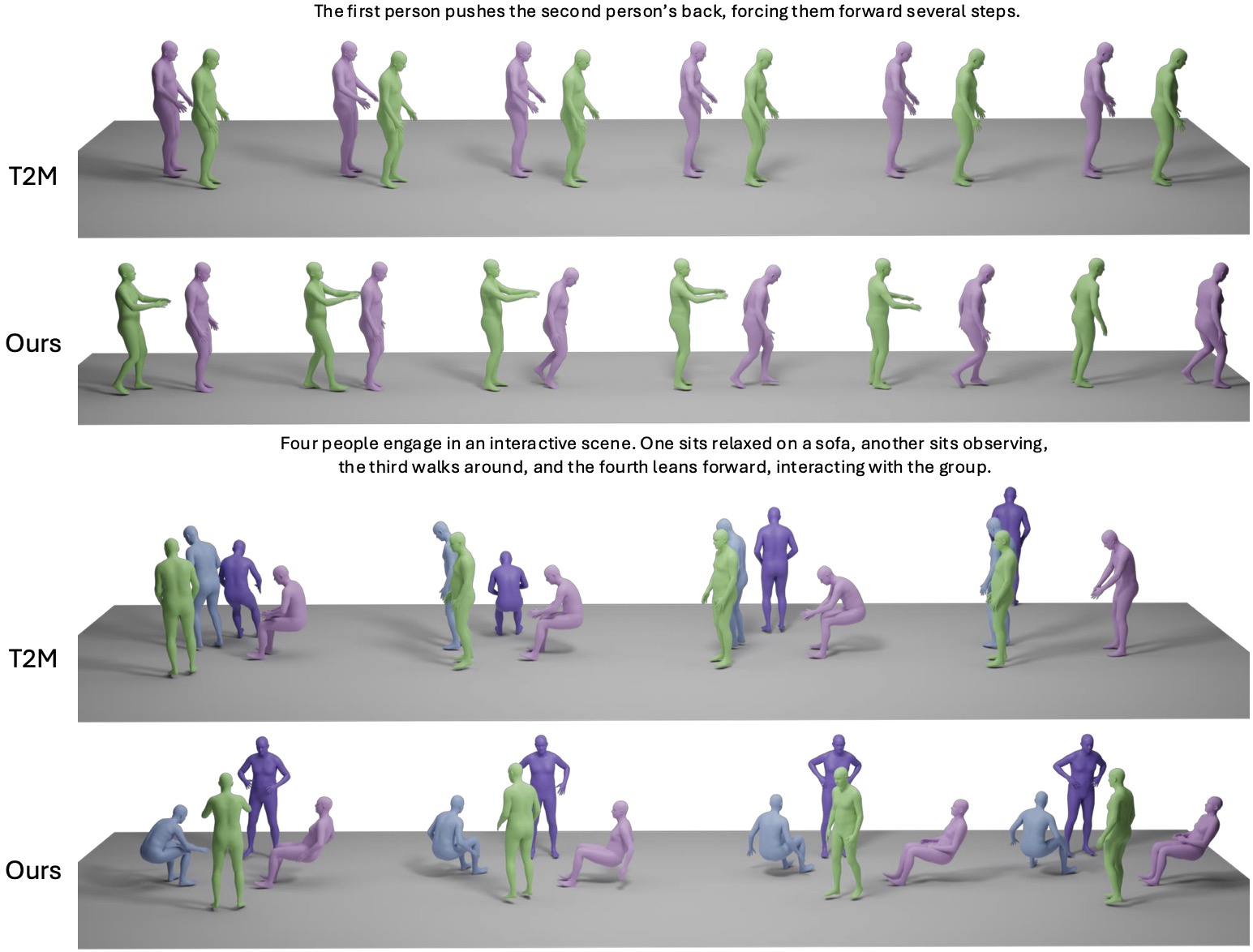
Text to Motion Generation
We present a comparison of text-to-motion generation results between our method and T2M [Guo et al . 2022b].
Motion to Text Generation
'Real' is the labeled caption in the dataset.

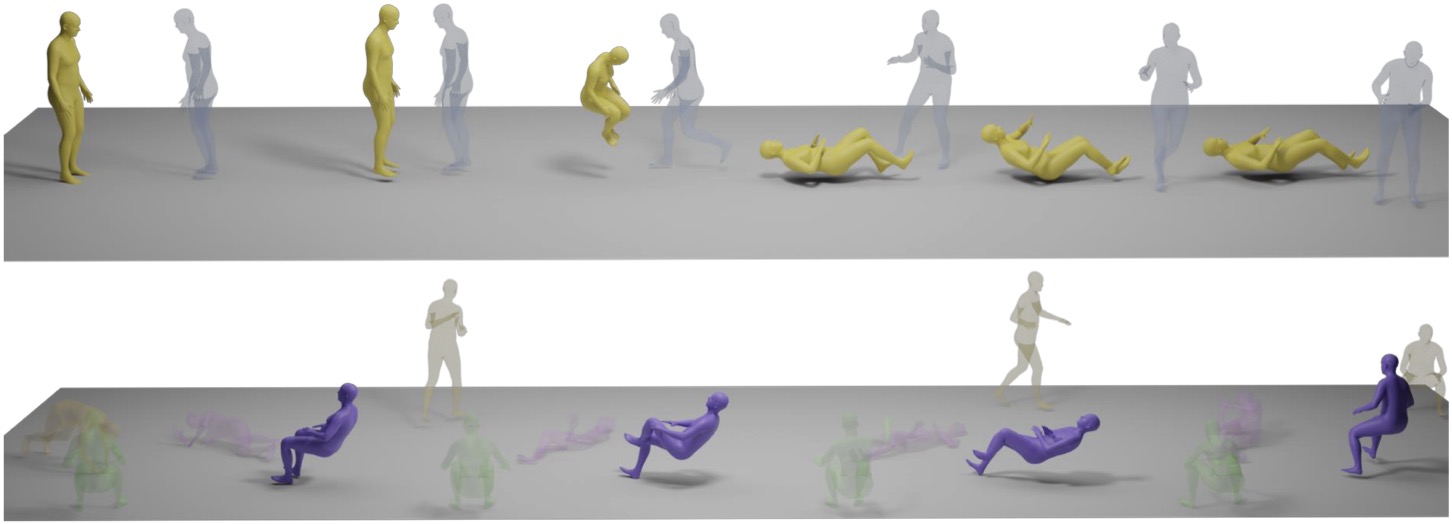
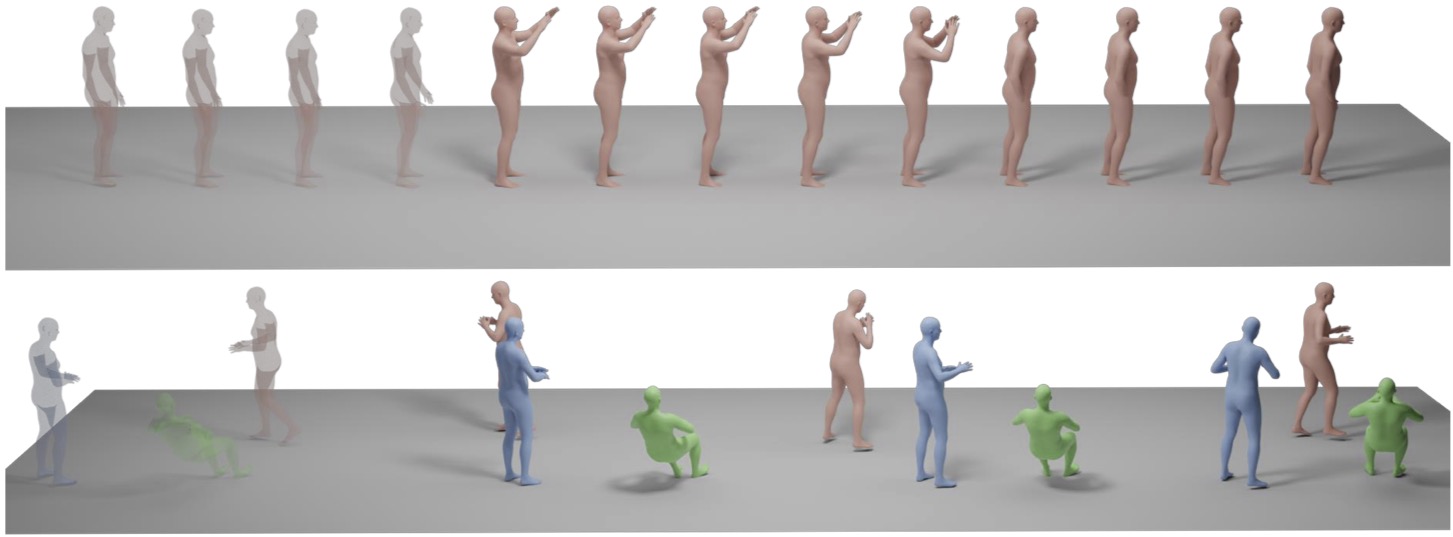
Motion Forecasting
Transparency indicates the initial motion used as a condition.
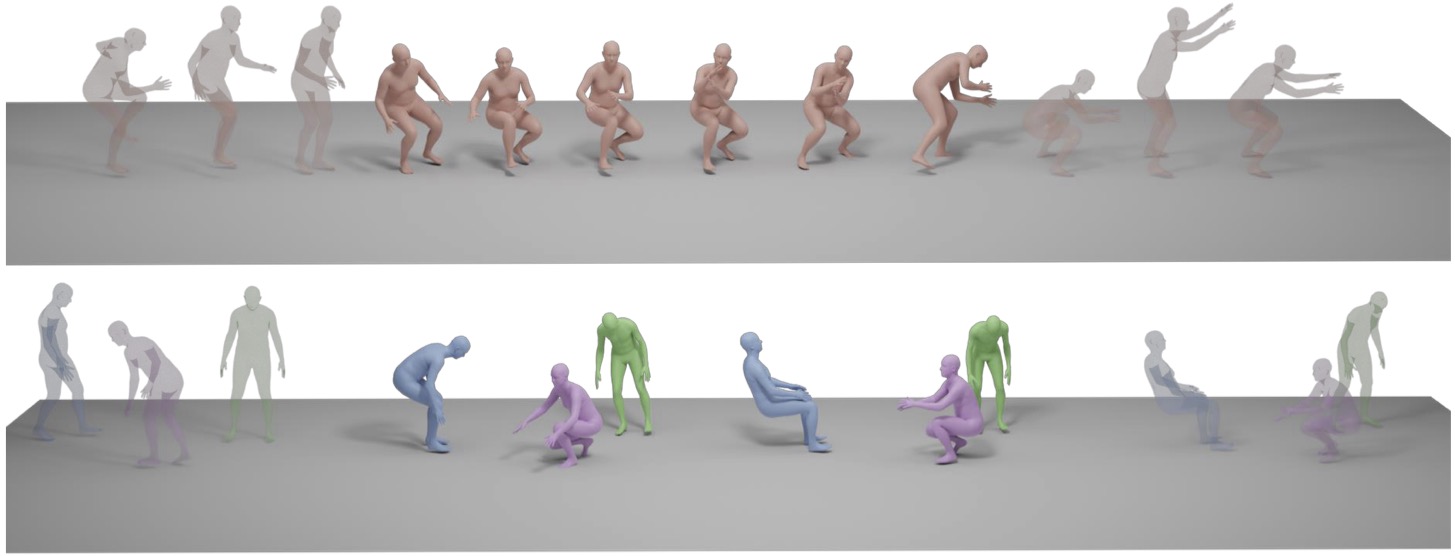
Motion Completion
Transparency indicates the initial and ending motions used as conditions.
Reaction Generation
Transparency indicates the motions of the persons used as conditions.